Debugging ohne Black Box: So trace‑st du jede Mail – von API‑Call bis Inbox
Debugging ohne Black Box: So trace‑st du jede Mail – von API‑Call bis Inbox
Einleitung
E-Mails zu verschicken ist einfach – bis etwas schiefgeht. Dann beginnt für Entwickler:innen oft der Blindflug: E-Mail-Zustellung debuggen fühlt sich an wie eine Black Box. Man feuert einen API-Call an den Mail-Service ab und hofft , dass die Mail beim Empfänger landet. Doch warum sie nicht ankommt (oder im Spam endet), bleibt häufig im Dunkeln. Bei Diensten wie Mailgun oder SendGrid fehlen im Alltag oft die nötigen Einblicke: Ob ein Nutzer die Mail geöffnet hat, versteckt sich irgendwo in Logdaten, und Spam-Beschwerden werden kaum transparent angezeigt 1 . Kurz gesagt: Ohne die richtigen Tools tappen selbst erfahrene Devs bei Mail-Problemen im Dunkeln.
Dabei sind die Auswirkungen gravierend. Transaktionale E-Mails (Passwort-Resets, Bestellbestätigungen, Benachrichtigungen) müssen zuverlässig ankommen – jeder Ausfall frustriert Nutzer und belastet den Support. Im Onboarding neuer Kunden können Zustellprobleme direkt zum Abbruch führen. MTTR bei E-Mail-Incidents (Mean Time To Resolve, die durchschnittliche Zeit bis zur Problemlösung) ist deshalb eine kritische Kennzahl. Dennoch dauert die Fehlersuche bei Mail-Versand häufig viel zu lange, weil entscheidende Informationen fehlen oder nur mühsam zusammengesucht werden können.
In diesem Artikel zeigen wir, dass es auch anders geht. Mit vollständiger Developer Observability – also durchsuchbaren Logs, Events in Echtzeit, Webhooks, Replay- und Testing-Tools – wird die berüchtigte Black Box transparent. Wir geben konkrete Best Practices und Troubleshooting-Playbooks an die Hand, wie du jede Mail vom API-Call bis zur Inbox trace‑st und so die Ursachen von Zustellproblemen in Minuten statt Stunden findest. Das reduziert den MTTR bei E-Mail-Problemen drastisch und sorgt dafür, dass deine Anwendung so zuverlässig kommuniziert, wie du es brauchst.
Event-Timeline & Visibility: Jede Station im Blick
Ein Schlüssel zum effektiven Debugging ist eine granulare Event-Timeline für jede gesendete Nachricht. Moderne E-Mail-Plattformen erzeugen eine Kette von Events, die den Lebenszyklus einer Mail abbilden: Accepted (vom System angenommen), Delivered (an den Zielserver übergeben), eventuell Opened / Clicked (vom Empfänger geöffnet oder Link geklickt), oder aber Bounced (Zustellung fehlgeschlagen) – bis hin zu Spam Complaint (Empfänger hat „Als Spam melden“ geklickt). Entscheidend ist, dass all diese Events mit Zeitstempel und Kontext erfasst werden . Nur so lässt sich nachvollziehen, was mit einer Mail nach dem Absenden tatsächlich passiert.
Stell dir vor, du suchst nach einer bestimmten Benutzer-E-Mail und bekommst eine lückenlose Timeline aller zugehörigen Ereignisse zurück. Du siehst z.B., dass die Mail um 12:00 Uhr angenommen und um 12:01 Uhr erfolgreich zugestellt wurde, der Empfänger sie um 12:05 Uhr geöffnet hat – oder alternativ, dass um 12:01 Uhr ein Bounce-Event mit Fehlercode einging. Eine solche Timeline liefert auf einen Blick Antworten auf Fragen wie: Wurde die Nachricht überhaupt zugestellt? Hat der Empfänger sie geöffnet? Wenn nein, warum nicht? Ohne Timeline müsste man diese Antworten mühsam aus einzelnen Logzeilen oder Reports zusammensuchen – ein zeitraubendes Unterfangen.
Granular getrackte Events sind daher Gold wert. Jeder Eintrag liefert Hinweise: Ein Delivered-Event bestätigt, dass der empfangende Mailserver die Nachricht akzeptiert hat (inklusive SMTP-Antwortcode). Ein Bounce-Event trägt den genauen SMTP-Fehlercode und eine Beschreibung, warum die Zustellung abgelehnt wurde. Ein Open-Event zeigt, dass die Mail den Weg bis zum Posteingang geschafft hat und gelesen wurde (sofern Tracking erlaubt ist). Diese Detailtiefe erlaubt es, in Sekundenschnelle zu diagnostizieren, an welcher Stelle im Mailflow es klemmt.
💡 Tipp: In vielen Fällen lässt sich schon aus der Reihenfolge und den Zeitabständen der Events erkennen, wo ein Problem liegt. Zum Beispiel deutet eine lange Lücke zwischen Accepted und Delivered auf Verzögerungen beim empfangenden Server hin, während ein sofortiges Bounce nach Accepted einen direkten Ablehnungsgrund liefert. Je vollständiger die Event-History, desto weniger Rätselraten beim Debugging der E-Mail-Logs.
Eine solche End-to-End-Sichtbarkeit nimmt das Guesswork aus dem E-Mail-Versand. Statt wie früher mühselig in Server-Logs nach einzelnen IDs zu suchen, sieht man heute idealerweise in der UI oder via API sofort, was mit einer Nachricht geschehen ist – nahezu in Echtzeit. Das verkürzt die Fehlersuche enorm: Entwickler können in Minuten Klarheit erlangen, statt stundenlang im Nebel zu stochern 2 .
Die Developer Console als X-Ray für den Mailflow
Wie kommt man nun zu dieser Durchsicht? Hier kommt die Developer Console ins Spiel – quasi der Röntgenblick für deine E-Mail-Pipeline . Eine gute Entwickler-Konsole bündelt alle relevanten Informationen und Werkzeuge an einem Ort. Anstatt auf verschiedene Tools verteilt zu sein, erhältst du eine zentrale „Command Center“-Sicht auf deinen Mailflow. Wichtige Funktionen einer solchen Console sind unter anderem:
- Suche & Timeline: Du solltest nach einer Message-ID, einer Empfängeradresse oder einem Betreff suchen können und unmittelbar die komplette Timeline dieser Nachricht sehen. Von der Annahme über Zustellung bis hin zu Öffnungen oder Bounces – alle Events werden in chronologischer Reihenfolge mit Details angezeigt. So identifizierst du schnell, wo etwas schiefging.
- Replay-Funktion: Was tun, wenn eine Mail aufgrund eines Fehlers nicht ankam? Mit Replay kannst du eine gescheiterte Nachricht erneut zustellen, nachdem du das Problem behoben hast. Beispiel: Du entdeckst einen Template-Bug, der einen Teil der Mails unzustellbar machte. Nach dem Fix klickst du auf „Replay“ und schickst die betreffenden Nachrichten einfach nochmal – ohne darauf warten zu müssen, dass der Nutzer die Aktion wiederholt.
- Webhook-Inspector: Webhooks liefern externe Events (z.B. Bounces, Complaints) in Echtzeit an deine Systeme. Ein integrierter Webhook-Inspector zeigt dir live, welche Webhook-Aufrufe gesendet wurden, mit Payload und Response. Damit kannst du prüfen, ob deine Anwendung die Events korrekt verarbeitet. Bonus: Die Möglichkeit, einen Webhook-Ereignis manuell noch einmal auszulösen (resenden), um z.B. einen fehlgeschlagenen Callback erneut zu testen.
- API Playground: Gerade für Entwickler hilfreich ist ein Bereich, in dem man API-Aufrufe direkt im Browser ausprobieren kann (mit gültigem API-Key, aber sicher isoliert). Ein solcher Playground erlaubt es, z.B. schnell eine Testmail über die API zu versenden oder eine Abfrage der Logs durchzuführen – ohne erst Code schreiben zu müssen. Das beschleunigt Integration und Debugging enorm.
Bisher gab es keinen großen E-Mail-Provider, der all dies nahtlos in einer Oberfläche vereint 3 . Entweder fehlen Suchmöglichkeiten, oder es gibt kein Replay, oder man muss für Webhook-Logs in externe Tools wechseln. Eine Unified Developer Console räumt mit diesem Stückwerk auf und bringt alles zusammen. So wird aus der Black Box eine gläserne Pipeline, in der du jede Nachricht verfolgen und bei Bedarf eingreifen kannst.
Beispielhafte Timeline-Ansicht für eine Nachricht (Postmark): Die UI zeigt alle Events einer E-Mail – vom Versand über die SMTP-Accepted-Bestätigung bis zur Zustellung und Öffnung. In diesem Beispiel wurde die Mail erfolgreich zugestellt und vom Empfänger geöffnet. Eine solche Übersicht ermöglicht es, den Weg jeder Mail lückenlos nachzuvollziehen, ohne in Logdateien suchen zu müssen.
Als Entwickler:in oder SRE bekommst du durch diese Console eine Art X-Ray-Blick auf den Mailflow . Statt auf Verdacht zu handeln, siehst du genau, was passiert (oder eben nicht passiert) ist. Das reduziert Support-Tickets à la „Könnt ihr herausfinden, was mit Mail X passiert ist?“ erheblich und gibt die Kontrolle zurück in Entwicklerhand. Im Optimalfall erscheinen alle Ereignisse wenige Sekunden nach ihrem Eintreten in der Console – echtes Live-Debugging wird möglich. Das Ergebnis: deutlich schnellere Fehlerdiagnose und -behebung , weniger Kommunikationsaufwand und eine robuste E-Mail-Zustellung als zuverlässiger Teil deiner Plattform.
Typische Fehlerbilder und wie man sie diagnostiziert
Trotz aller Visibility und Tools gilt es natürlich immer noch, die richtigen Schlüsse aus den Daten zu ziehen. Im Folgenden gehen wir auf häufige Fehlerbilder bei der E-Mail-Zustellung ein – von Hard Bounces bis zu Authentifizierungsproblemen – und zeigen, wie man sie erkennt und behebt. Hier kommen auch die Bounce-Codes ins Spiel, also die SMTP-Antwortcodes, die Mailserver bei Problemen zurückmelden. Wir erklären, was typische Codes bedeuten und wie man darauf reagiert.
550 Hard Bounces (dauerhafte Fehler)
Wenn eine Mail mit einem 550er-Code zurückgewiesen wird, handelt es sich fast immer um einen Hard Bounce – ein permanentes Zustellproblem. SMTP-Statuscodes, die mit „5“ beginnen, signalisieren dem Absender: **Diese Mail kann nicht zugestellt werden, ein ** erneuter Versuch ist zwecklos 4 . Häufigster Fall: 550 5.1.1 – User unknown , d.h. die empfangende Adresse existiert nicht (Tippfehler oder alte Adresse) 5 . Andere Gründe für 550er Bounces sind z.B. „Mailbox unavailable“ (Postfach deaktiviert), „Rejected for policy reasons“ (vom empfangenden Server blockiert, z.B. Spamverdacht) oder „Address blacklisted“ .
In der Developer Console oder im Log sieht man bei einem Hard Bounce den exakten Fehlertext des empfangenden Mailservers. Dieser Text ist Gold wert: Er verrät den Grund der Ablehnung . Einige Beispiele:
- „550 5.1.1 The email account does not exist“ – Adresse ungültig.
- „550 5.2.1 Inbox full“ – das Postfach ist voll (permanenter Fehler, der Empfänger muss erst Mails löschen).
- „550 5.7.1 Blocked by XXX“ – der Server hat die Mail wegen Inhalts- oder Absenderkriterien abgelehnt (häufig Spamfilter).
Bounce-Detailansicht (Postmark): Hier sieht man, dass die Nachricht als Hard Bounce gekennzeichnet ist. Der SMTP-Error „550 5.1.2“ mit Beschreibung deutet auf eine dauerhaft unzustellbare Domain hin (Domain fehlerhaft oder nicht existent). Solche Details helfen, sofort die Ursache einzugrenzen – in diesem Fall müsste man die Empfängeradresse prüfen.
Diagnose & Lösung: Bei 550er-Bounces ist klar: Hier braucht Wiederholen allein nicht zu helfen – man muss die Ursache beseitigen. Ist die Empfängeradresse falsch oder veraltet, kann man nichts tun außer sie zu korrigieren oder aus dem Verteiler zu nehmen. Wurde die Mail als Spam abgelehnt (5.7.x-Codes), sollte man den Inhalt und die Absender-Reputation überprüfen. Wichtig: Adressen, die einen Hard Bounce erzeugen, sollte man sofort auf eine Suppression List setzen (bzw. der E-Mail-Service tut dies oft automatisch), damit zukünftige Versendungen an diese Adresse unterbleiben. Jede weitere Mail an eine nicht existierende Adresse schadet nur deinem Absender-Ruf.
💡 Tipp: Analysiere regelmäßige Hard Bounces, um Muster zu erkennen. Häufen sich z.B. 5.1.1-Bounces, könnten viele Nutzer ihrer Adressen geändert haben – Zeit für einen Cleanup des Verteilers. Bei 5.7.1-Policy-Bounces sollte man seine Inhalte oder Authentifizierung (SPF/DKIM) prüfen, da hier Spamfilter anschlagen.
421 Soft Bounces & Throttling (temporäre Fehler)
Im Gegensatz zum 5xx-Code bedeutet ein 4xx SMTP-Code : „Nicht geklappt, aber es könnte beim nächsten Versuch funktionieren.“ Diese Soft Bounces weisen auf temporäre Zustellprobleme hin 4 . Ein klassisches Beispiel ist „421 4.7.0 Temporary Deferred“ – der Empfänger-Server nimmt die Mail gerade nicht an, will es später nochmal probieren. Gründe dafür können Überlastung oder Wartung beim Empfänger sein. Auch Throttling fällt in diese Kategorie: Einige Mailserver (v.a. große wie Gmail) drosseln die Annahme, wenn plötzlich sehr viele Mails auf einmal kommen. Sie antworten dann mit einem 421/450-Code, was signalisiert „langsamer senden, ich komme gerade nicht hinterher“.
Wie erkennt man Soft Bounces? In der Timeline erscheint nach dem Accepted zunächst kein Delivered , stattdessen ein Bounce-Event mit 4xx-Code, oft gefolgt von einem erneuten Zustellversuch. Gute Mail-Backends retry automatisch bei Soft Bounces – z.B. im Abstand von 5, 15, 30 Minuten – bis eine gewisse Zeit verstrichen ist. Solange muss man erst mal nicht eingreifen. Wenn die Mail beim zweiten oder dritten Versuch doch noch angenommen wird, taucht schließlich ein Delivered-Event auf. Bleibt der Bounce jedoch bestehen (auch nach x Versuchen), wird er meist in einen Hard Bounce „umgewandelt“ oder die Mail als unzustellbar markiert.
Diagnose & Lösung: Einzelne Soft Bounces sind meist unkritisch – die meisten löst das System selbst, indem es später erneut sendet. Kritisch wird es, wenn Soft Bounces gehäuft auftreten oder gar ein großer Teil deiner Mails deferred wird. Dann lohnt ein Blick auf die Ursachen: Sind es bestimmte Domains, die dich drosseln (z.B. „421 Slow down, sending too fast“ bei Gmail)? Dann solltest du dein Versandtempo an diese Domain reduzieren oder nach und nach steigern (Stichwort Warmup, siehe unten). Ist es Mailbox full (üblicher 4.2.2 Code), können deine Mails dort erst ankommen, wenn der Nutzer Speicher freiräumt – hier kannst du wenig tun außer abwarten. Generell gilt: Soft Bounce = temporäres Problem , aber Warnsignal.
💡 Tipp: Überwach deinen Versand auf ungewöhnliche Häufungen von Soft Bounces. Ein plötzlicher Anstieg kann bedeuten, dass ein großer Mail-Provider dich vorübergehend ausbremst. Oft hilft es schon, die Sendefrequenz zu reduzieren. Viele ESPs (Email Service Provider) ermöglichen sog. Batching/Pausing pro Domain, um z.B. an Gmail nur X Mails pro Minute zu senden und so Throttling zu umgehen.
Blocklists: Wenn deine IP auf der schwarzen Liste steht
Ein Albtraum jedes E-Mail-Versenders sind Blocklists (auch Blacklists genannt). Das sind öffentliche schwarze Listen von IP-Adressen oder Domains, die als Spamquellen aufgefallen sind. Landest du dort, lehnen viele empfangende Mailserver deine Mails kategorisch ab – meist mit einer Fehlermeldung, die auf die Liste verweist. Zum Beispiel: „550 5.7.1 blocked using bl.spamcop.net; see https://www.spamcop.net/bl.shtml“ . In der Praxis sieht man Blocklist-Bounces häufig bei Freemailern oder Enterprise-Servern, die strikte Anti-Spam-Maßnahmen fahren.
Diagnose: Ein Indiz ist, dass alle Mails an eine bestimmte Gruppe von Empfängern plötzlich geblockt werden, oft mit ähnlichen Fehlermeldungen. Wenn z.B. sämtliche Empfänger bei Microsoft (Hotmail/Outlook) mit einem 550 abwehren, könnte deine IP auf der Microsoft SNDS/Spamhaus-Liste gelandet sein. Viele Blocklist-Bounce-Meldungen enthalten einen Link oder Namen der Liste (Spamhaus, Spamcop, etc.). Mit Tools wie MX Toolbox oder der Webseite der jeweiligen Blocklist kann man dann prüfen, ob die eigene Absender-IP gelistet ist.
Lösung: Hier heißt es sofort handeln . Erstens: Ursachen finden. Typische Auslöser sind hohe Spam-Beschwerderaten, Versenden an viele ungültige Adressen (Spam-Traps) oder ein kompromittiertes Konto, das Spam versendet. Diese Probleme müssen behoben werden, sonst bringt jede Delisting-Anfrage nur kurzfristig Erfolg. Zweitens: Delisting beantragen. Jede seriöse Blocklist bietet einen Prozess, um unschuldige oder geläuterte Absender wieder zu entfernen. Das kann von automatischen Web-Formularen bis zu manuellen E-Mails reichen. Während der Listung sollte man das Versandvolumen reduzieren und besonders auf Reputation achten.
🚨 Achtung: Eine Blocklist-Listung ist ein ernstes Alarmzeichen. Sie wirkt sich direkt auf die Zustellrate aus, denn viele große Mailanbieter nutzen diese Listen. Ignoriert man das, riskiert man massive Zustellausfälle. Nicht versuchen, einfach über eine andere IP weiterzusenden , ohne das Problem zu lösen – das sogenannte IP-Hopping endet meist damit, dass auch die neuen IPs bald gelistet werden. Lieber Ursachen abstellen, Reputation langsam zurückgewinnen und dann delisten lassen.
Rate Limits: Grenzen des Versands erkennen
Neben Blockierungen durch Empfänger können auch Versand-Limits Probleme bereiten. Viele E-Mail-Provider setzen Rate Limits oder Quotas, um ihre Infrastruktur und Reputation zu schützen. Das kann mehrere Formen annehmen:
- API-Rate-Limits: Die API, über die du Mails sendest, erlaubt nur X Aufrufe pro Sekunde. Überschreitest du das, bekommst du z.B. HTTP 429 „Too Many Requests“. In Logs würdest du sehen, dass Send-Aufrufe abgelehnt wurden.
- Hourly/Daily Quotas: Manche Services (insbesondere in kostenlosen Plänen) limitieren die Anzahl versendeter Mails pro Stunde oder Tag. Wird das Limit erreicht, gehen weitere Send-Versuche entweder in eine Warteschlange oder schlagen fehl.
- Empfängerseitige Limits: Wie schon bei Throttling erwähnt, limitieren große Mailbox-Provider wie Gmail, Yahoo etc. die Anzahl gleichzeitiger Verbindungen oder Mails pro Absender pro Zeiteinheit. Das äußert sich dann wieder in 421-Deferrals, was streng genommen auch eine Art Rate Limiting ist.
Diagnose: Wenn E-Mails gar nicht erst rausgehen, obwohl das System verfügbar ist, lohnt ein Blick auf die Provider-Logs oder Dashboard-Meldungen . Viele ESPs zeigen an, wenn man an ein Limit stößt („Sending rate exceeded“ o.ä.). Bei API-Limits liefern die HTTP-Responses klare Hinweise. Empfängerseitige Limits erkennt man wie gesagt an vermehrten Soft Bounces/Deferrals in der Event-Timeline. Ein Anzeichen ist auch, wenn die Versandlatenz plötzlich steigt, weil der Provider intern drosselt.
Lösung: Kurzfristig hilft oft Drosselung – z.B. das Versenden auf mehrere Minuten verteilen, statt alles auf einmal rauszuschicken. Längerfristig sollte man mit dem Anbieter sprechen oder den Plan upgraden, wenn man regelmäßig an Grenzen stößt. Für große Volumen sind dedizierte IPs oder ein Verteilen auf mehrere IPs übliche Strategien, um Limits zu umgehen (wobei das orchestriert erfolgen muss, sonst schadet es der Reputation). Generell gilt: Kenne die Limits deines Systems und plane deine Mail-Sends entsprechend. Im Zweifel im Vorfeld beim Anbieter nachfragen, ab welcher Last man mit Drosselung rechnen muss.
Cold Starts: Warming Up ist Pflicht
Du hast einen neuen Mailserver oder eine frische IP-Adresse? Dann aufgepasst: Cold Starts im E-Mail-Versand können tückisch sein. „Cold“ bedeutet, die Absender-IP oder Domain hat noch keinerlei Reputation bei den großen Mailbox-Providern. Wenn du nun direkt mit hohem Volumen sendest, werden dich viele Empfänger misstrauisch behandeln – Ergebnis: entweder landen die Mails im Spam, oder du siehst eine Menge 4xx-Deferrals (Throttling), eventuell sogar einige 5xx-Blocks wegen „Policy“.
Diagnose: Ein Cold-Start-Problem äußert sich darin, dass speziell bei den ersten Sendungen an z.B. Gmail, Outlook, Yahoo auffällig viele Verzögerungen oder Soft Bounces auftreten, obwohl an der Infrastruktur alles zu stimmen scheint. Außerdem können Open-Rates ungewöhnlich niedrig sein, was darauf hindeutet, dass Mails im Spamordner landen. Mit einer guten Logging/Monitoring-Lösung erkennst du: Die Bounces verteilen sich nicht gleichmäßig, sondern konzentrieren sich auf bestimmte ISPs, und oft mit Meldungen, die auf „Rate limit“ oder „Temporary block“ hindeuten.
Lösung: Das Zauberwort heißt IP Warm-up . Dabei steigert man das Versandvolumen über eine neue IP langsam und kontrolliert . Z.B. am ersten Tag nur 100 Mails, am zweiten 500, am dritten 1.000 usw., über mehrere Wochen, bis zum gewünschten Volumen. Wichtig ist, zuerst an die engagiertesten Empfänger zu senden (z.B. Kunden, die kürzlich aktiv waren), damit Öffnungen/Klicks generiert werden und wenige Beschwerden. So sammelt die neue IP positive Reputation. Während des Warm-ups genau beobachten: Gibt es Blockierungen, etwas Tempo rausnehmen. Viele ESPs haben Warm-up Guides – im Zweifel deren Empfehlungen folgen. Geduld zahlt sich hier aus.
💡 Tipp: Plane einen IP/Domain-Wechsel frühzeitig. Wenn du z.B. von einem alten Provider zu einer eigenen IP umziehst, lass zunächst einen Teil der Mails über die neue IP laufen und den Rest noch über die alte, um einen sanften Übergang zu schaffen. Ein abruptes Umschalten aller Mails auf eine „kalte“ IP ist eine Einladung zu Zustellproblemen.
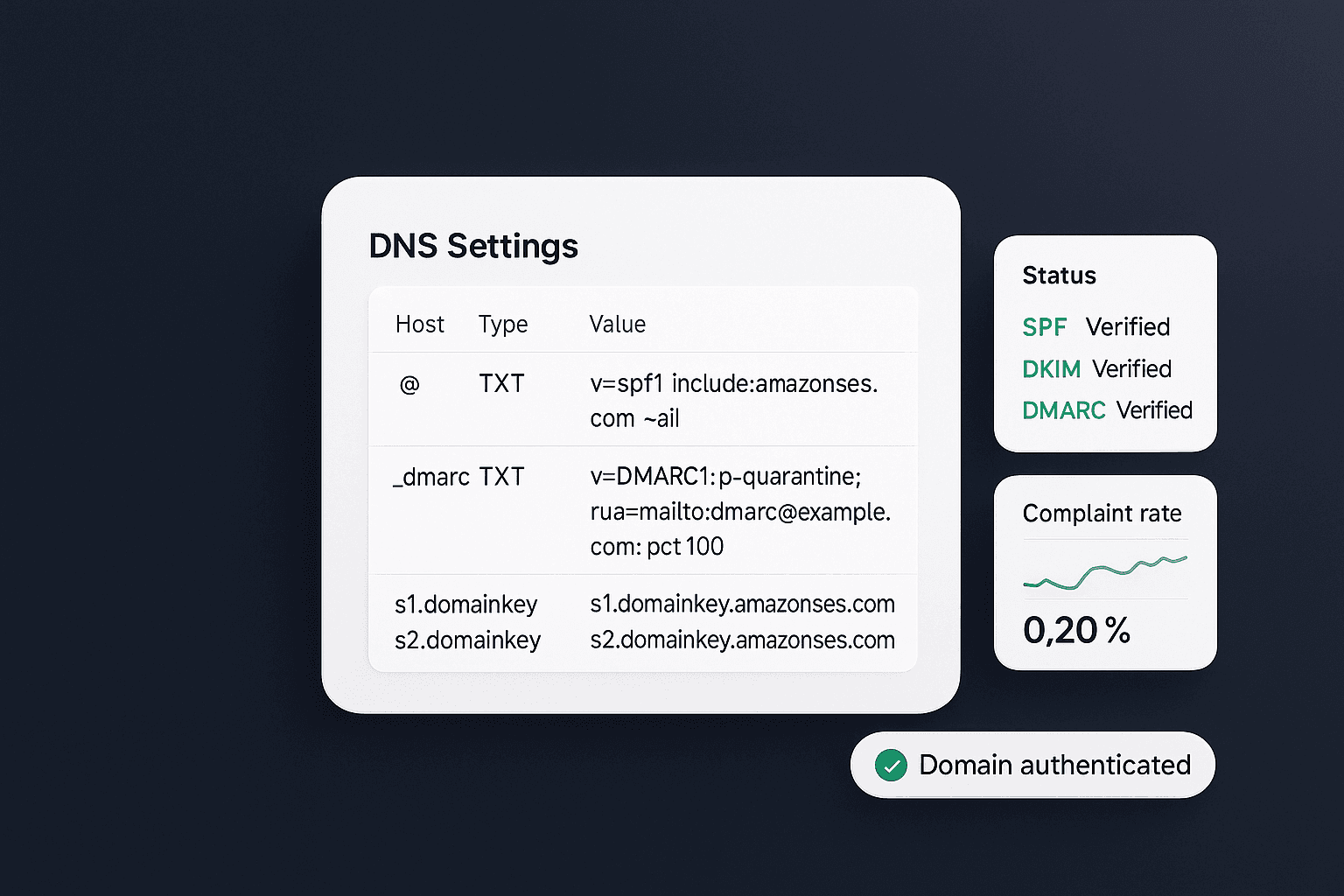
Fehlende Authentifizierung (SPF/DKIM) & DNS-Probleme
Zuletzt ein Klassiker, der leider immer wieder vorkommt: fehlende oder falsche DNS-Konfiguration der Absenderdomain. Ohne gültige DKIM-Signatur und SPF-Eintrag schickt man E-Mails praktisch mit offener Tür ins Rennen – viele Provider werden solche Mails ablehnen oder als verdächtig einstufen. Besonders streng wird es, wenn der Absender eine Domain mit DMARC -Policy hat: Ist die Mail nicht korrekt authentifiziert (z.B. weil DKIM fehlt oder fehlschlägt), lehnt der Empfänger sie je nach DMARC-Einstellung direkt ab. Google z.B. reagiert auf so etwas mit dem Fehler „550 5.7.26 Unauthenticated email from [Domain] is not accepted due to domain’s DMARC policy“ – ein klares No-Go .
Diagnose: Dieses Fehlerbild ist relativ einfach zu erkennen, da es alle Empfänger betrifft und sofort auftritt. Wenn plötzlich gar keine Mails mehr zugestellt werden, prüfe als erstes die DNS-Settings: Ist die Domain verifiziert? Stimmen die SPF-Records (inkl. aller „include:“ Einträge)? Ist ein DKIM-Schlüssel hinterlegt und stimmt der Selector? Ein weiterer Hinweis: In Bounce-Meldungen tauchen Worte auf wie „unauthenticated“, „SPF fail“, „DKIM invalid“. In der Developer Console eines guten ESP siehst du evtl. auch Warnungen, wenn du ohne gültige Authentifizierung sendest.
Lösung: Klar – DNS-Einträge korrigieren . Richte SPF so ein, dass deine Versand-Infrastruktur abgedeckt ist (typisch: v=spf1 include:emailprovider.com ~all ). Setze DKIM auf, indem du einen öffentlichen Schlüssel als DNS-TXT-Record hinterlegst und das Signieren im Mail-Provider aktivierst. Überprüfe beides mit den Tools deines Providers oder externen Validatoren. Wichtig: Falls du eine strikte DMARC-Policy (p=reject) auf deiner Domain hast, musst du SPF/DKIM unbedingt vor dem Senden richtig konfiguriert haben, sonst werden deine Mails fast überall geblockt.
🚨 Achtung: Fehlende Authentifizierung ist einer der häufigsten vermeidbaren Gründe für Zustellprobleme. Es lohnt sich, hier doppelt zu prüfen. Viele Provider (z.B. Office365, Yahoo) verschärfen laufend ihre Anforderungen – was gestern noch „irgendwie durchging“, wird morgen eventuell geblockt. Also: SPF, DKIM, DMARC – diese drei sollte jede versendende Domain haben. Dein E-Mail-Service wird dich dabei mit Anleitungen unterstützen; nimm diese nicht auf die leichte Schulter.
Nun haben wir die gängigsten Fehlerursachen betrachtet und wie man sie erkennt. Im nächsten Schritt geht es darum, auf solche Incidents auch schnell zu reagieren – mit Metriken, Alerting und klaren Runbooks für den Bereitschaftsdienst (On-Call).
Metriken & Runbooks für On‑Call: Schnell reagieren, schneller beheben
Selbst mit bestem Monitoring passieren E-Mail-Incidents – wichtig ist dann, wie schnell du darauf reagierst und sie löst. MTTA (Mean Time To Acknowledge) und MTTR (Mean Time To Resolve) sind Kennzahlen, die es zu minimieren gilt. Hier ein paar Tipps, wie du durch Metriken und klare Abläufe die E-Mail-Zustellung debuggen kannst, ohne lange im Dunkeln zu tappen.
Reaktive Metriken: Alerts auf Bounces & Co.
Damit du überhaupt weißt, dass ein Problem vorliegt, brauchst du die richtigen Metriken und Alerts. Einige bewährte Kennzahlen und Schwellenwerte:
- Bounce-Rate (Hard Bounces): Ein plötzlicher Anstieg der Hard-Bounce-Rate (z.B. >5% innerhalb von 1 Stunde) sollte einen Alarm auslösen. Das kann bedeuten, dass etwa ein DNS-Fehler vorliegt (alle Ziele lehnen ab) oder eine wichtige Empfängerdomain blockt dich.
- Spam-Complaint-Rate: Jede Spam-Beschwerde ist kritisch. Steigt die Complaint-Rate über z.B. 0,5% an einem Tag, stimmt etwas nicht (vielleicht ein problematischer Mailing oder ein gekapertes Konto, das Spam versendet). Hier sollte on-call benachrichtigt werden, da eine hohe Complaint-Rate schnell zu Blocklistings führen kann.
- Delivery-Rate/Volume Dips: Wenn das System normalerweise 100 E-Mails/Minute sendet und plötzlich nahe 0 liegt, stimmt etwas nicht – möglicherweise ein internes Problem oder der Provider hat den Account pausiert. Ein Alert „Sendervolumen unter Schwellwert X“ kann helfen, Ausfälle sofort zu erkennen, noch bevor User-Tickets reinkommen.
- Latency der Mail-Zustellung: Zieht sich die Zeit von Accepted bis Delivered ungewöhnlich in die Länge (z.B. >10 Minuten im Schnitt, wo sonst 10 Sekunden üblich sind), kann das auf generelle Probleme oder Throttling hindeuten. Solche Verzögerungen spüren Nutzer zwar indirekt, aber sie sind oft Vorboten größerer Probleme.
Mit solchen Metriken im Blick kann der On-Call-Ingenieur proaktiv reagieren, anstatt erst durch Nutzerbeschwerden alarmiert zu werden. Moderne E-Mail-Plattformen bieten oft eingebaute Dashboards für Bounce- und Engagement-Raten – nutze diese und setze individuelle Schwellen, die zu deinem Business passen.
💡 Tipp: Lege für jeden Alarm direkt ein Mini-Runbook fest: Wenn z.B. die Bounce-Rate-Alert angeht, weiß der On-Call sofort, welche Checks als erstes durchzuführen sind (DNS prüfen, Blocklist-Check, spezifische Domain auffällig?). So sparst du kostbare Minuten im Ernstfall.
Incident Response: Troubleshooting & Replay-Playbooks
Kommt es tatsächlich zu einem Incident, zählt jede Minute. Hier zahlt sich die zuvor beschriebene Observability aus: Ein On-Call sollte in der Lage sein, binnen Minuten die Ursache einzugrenzen. Nehmen wir ein Beispiel-Playbook für einen E-Mail-Incident:
- Alert: Bounce-Rate hoch – On-Call bekommt Alarm, dass z.B. 10% der Mails in den letzten 15 Minuten gebounced sind.
- Erster Check in der Developer Console: Filter nach den letzten Bounces. Erkenntnis: alle Bounces betreffen *@gmail.com Adressen mit dem Code „5.7.1“. Offensichtlich blockiert Gmail unsere Mails gerade.
- Ursache analysieren: Im Bounce-Detail steht als Grund evtl. „Content rejected“ oder „Blocked for spam“ . Parallel prüfen: Wurde kürzlich ein neuer Inhalt/Mailing ausgerollt? Spam-Complaints gestiegen? Möglicherweise hat ein fehlerhafter Newsletter unseren Ruf ramponiert.
- Maßnahmen einleiten: Falls ein bestimmter Mailing verantwortlich ist – sofort pausieren. Feedback-Loop/Complaint-Daten checken, Abmeldelink funktionieren? Ggf. mit Gmail Postmaster Tools schauen, ob ein spezifisches Problem vorliegt (z.B. Authentication gebroken). Außerdem könnte man den Provider-Support einschalten , falls es ein False Positive ist.
- Wiederherstellen: Nachdem die Ursache adressiert ist (fehlerhafte Kampagne gestoppt z.B.), schauen wir, was mit den fehlgeschlagenen Mails passiert ist. Hier kommt Replay ins Spiel: Die Developer Console listet 500 gebouncte Transaktionsmails (vielleicht Bestellbestätigungen). Diese können wir nun – sofern die Ursache behoben ist – gezielt erneut versenden. Im Idealfall per Mehrfachauswahl und Klick auf „Replay“ anstoßen, oder via API-Skript. So stellen wir sicher, dass kein Nutzer leer ausgeht, obwohl Gmail uns temporär blockt hat.
- Nachverfolgung: Im Anschluss beobachten, ob die Bounces zurückgehen. Eventuell muss man in den nächsten Tagen das Volumen gedrosselt halten oder andere Maßnahmen ergreifen, bis die Reputation sich erholt hat. Alles dokumentieren für’s Post-Mortem.
Ein anderes Szenario: Replay-gestütztes Debugging nach Rollout. Angenommen, ein neues Update hat einen Fehler in E-Mail-Templates verursacht, wodurch alle Passwort-Reset-Mails ins Leere liefen (z.B. weil ein Platzhalter den Versand scheitern ließ). Früher eine Katastrophe – Nutzer könnten sich nicht einloggen. Mit guter Observability merkt der On-Call aber sofort: „Moment, seit dem Deployment vor 10 Minuten bouncen alle Password-Resets mit Fehler XY.“ Man rollt das fehlerhafte Update zurück oder fixt den Bug in Rekordzeit. Und jetzt der Clou: Alle fehlgeschlagenen Mails der letzten Minuten lassen sich per Replay erneut senden, nachdem der Fix live ist. Die betroffenen Nutzer bekommen also mit minimaler Verzögerung doch noch ihre Mails, ohne dass sie erneut etwas anfordern mussten. Der Incident ist gelöst, bevor viele Tickets aufschlagen.
💡 Tipp: Nutze die Replay-Funktion auch präventiv in Staging. Viele Fehler lassen sich vermeiden, indem man neu erstellte Templates oder Änderungen zunächst mit echten Beispieldaten in einer Testumgebung an sich selbst sendet. Einige Developer Consoles erlauben es, eine vergangene Transaktion aus Prod in der Staging-Umgebung „nachzuspielen“. So kannst du realistische Tests machen, ohne Benutzer zu beeinflussen.
Durch solche Abläufe sinkt die durchschnittliche Ausfallzeit drastisch. Wenn früher ein E-Mail-Problem oft erst nach Stunden bemerkt und in weiteren Stunden gelöst wurde, reden wir jetzt von Minuten. MTTA/MTTR verbessern sich enorm , weil das Team nicht mehr im Nebel stochert, sondern gezielt handeln kann. Die Kombination aus Alerts, klaren Runbooks und mächtigen Tools (Search, Webhooks, Replay) macht’s möglich.
Fazit: Unified Developer Experience – keine halben Sachen mehr
E-Mail gehört zum Lebensnerv vieler Anwendungen. Es ist paradox, dass Entwickler-Teams zwar Observability und DevOps-Praktiken auf ihre Microservices anwenden, der E-Mail-Versand aber oft noch als undurchsichtige Black Box behandelt wird. Das muss nicht sein. Wie wir gezeigt haben, lassen sich mit den richtigen Werkzeugen alle Aspekte der E-Mail-Zustellung transparent machen und steuern. Von der ersten Anfrage an die API bis zur letztlichen Zustellung ins Postfach – jeder Schritt ist tracebar.
Unser Plädoyer: Schafft eine Unified Developer Console für eure E-Mail-Plattform. Bringt Logs, Events, Webhook-Viewer, Replay und Testing in eine Oberfläche (bzw. API). Die Vorteile sind klar: schnellere Fehleranalyse, weniger Support-Tickets, proaktives Erkennen von Problemen und letztlich zufriedene Endnutzer, die ihre E-Mails pünktlich erhalten. Ein integriertes Toolset schlägt Insellösungen um Längen – das haben wir auch bei den existierenden Anbietern beobachtet. Mailgun etwa bietet 30 Tage Logs und Webhooks, aber kein Replay; SendGrid hat ein UI für Stats, aber detaillierte Event-Analysen bleiben schwierig; Postmark glänzt mit 45-Tage-Search 1 , aber auch hier fehlt die Verknüpfung aller Features in einem Flow. Warum also Kompromisse eingehen?
Bei Fluxomail (unser fiktives Beispiel für eine moderne Mail-Plattform) verfolgen wir genau diesen ganzheitlichen Ansatz. Die Entwickler-Experience steht an erster Stelle: Suche, Live-Events, Webhook-Inspector, Replay, API-Spielwiese – alles unter einem Dach. Dadurch reduzieren wir die Komplexität für Entwickler drastisch. Wer einmal erlebt hat, wie schnell sich ein kniffliger Zustellfehler mit den richtigen Tools finden lässt, will nie wieder zurück zu blindem Herumstochern oder Warten auf Support-Auskünfte.
Am Ende des Tages bedeutet das: E-Mail-Inzidenzen lösen sich vom Angstthema zur Routineaufgabe. Anstatt panisch zu fragen „Mail X ist nicht angekommen, was tun?!“, hat das Team einen kühlen Kopf, öffnet die Developer Console, trace‑t die Mail und sieht sofort Ursache und Lösung. Debugging ohne Black Box eben – genau so, wie es sein sollte.
Damit wird E-Mail vom Unsicherheitsfaktor zu einem verlässlichen Teil eures Stacks. Und ihr könnt euch wieder dem Wichtigen widmen: großartige Features bauen, statt Phantom-Fehlern in der Mailzustellung hinterherzujagen. Viel Erfolg beim Implementieren eurer eigenen E-Mail-Observability – und happy Debugging!
file://file-KDkvKmFLUTBC7U2Cgi59GH
2 Access 45 days of your transactional email content and events | Postmark
4 5 Email bounces: why they happen & how to handle them | Postmark